Text Processing Workflows#
A deep dive into natural language processing is outside the scope of this course, but we’ll introduce a few building blocks here for working with text data.
"Natural language processing (NLP) is an interdisciplinary subfield of computer science and linguistics. It is primarily concerned with giving computers the ability to support and manipulate speech. It involves processing natural language datasets, such as text corpora or speech corpora, using either rule-based or probabilistic (i.e. statistical and, most recently, neural network-based) machine learning approaches. The goal is a computer capable of "understanding" the contents of documents, including the contextual nuances of the language within them" (Wikipedia)
Acknowledgements#
The explanations and examples in this section are adopted from the Distributed AI Research Institute’s “Fundamentals of NLP” resource.
Eric Saravia, “Chapter 1 - Tokenization, Lemmatization, Stemming, and Sentence Segmentation” Fundamentals of NLP (DAIR, 19 March 2020)
Setup#
We’ll start explore some of these workflows using Python’s spaCy library.
First, we need to install and load spaCy.
There will be lots of output- don’t panic!
#!pip install -q spacy # install library
!pip install -U spacy-lookups-data
import spacy # import library
!spacy download en_core_web_md # download program components
nlp = spacy.load('en_core_web_md') # load language model
from spacy import displacy
from spacy.lookups import Lookups
!pip install -q gensim
import gensim
from gensim.corpora import Dictionary
from gensim.models import LdaModel
Tokenization#
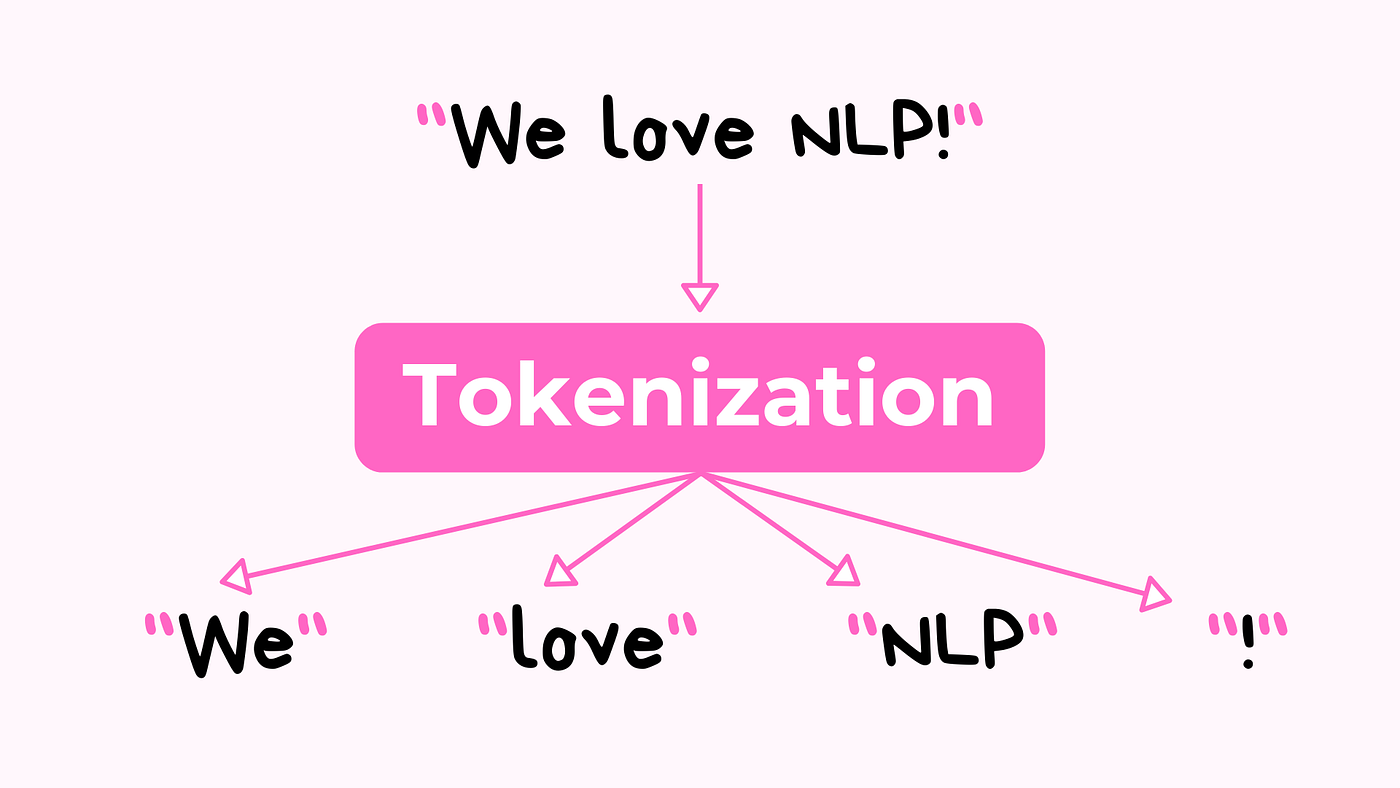
Tokenization involves extracting tokens from a piece of text.
doc = "Cheer cheer for old Notre Dame" # string
for i, w in enumerate(doc.split(" ")): # tokenize string
print("Token " + str(i) + ": " + w) # output tokens
Token 0: Cheer
Token 1: cheer
Token 2: for
Token 3: old
Token 4: Notre
Token 5: Dame
Lemmamitization#

Lemmatization reduces tokens to their base form.
doc = nlp("Our words are buttressed by our deeds, and our deeds are inspired by our convictions.") # string, courtesy of Fr. Hesburgh
for word in doc: # iterate over string
print(word.text, "=>", word.lemma_) # lemmatize tokens
Stemming#

Stemming determines what base form a token is derived or inflected from.
from nltk.stem.snowball import SnowballStemmer # import statement
stemmer = SnowballStemmer(language='english')
doc = "Our words are buttressed by our deeds, and our deeds are inspired by our convictions." # string, courtesy of Fr. Hesburgh
for token in doc.split(" "):
print(token, '=>' , stemmer.stem(token))
Our => our
words => word
are => are
buttressed => buttress
by => by
our => our
deeds, => deeds,
and => and
our => our
deeds => deed
are => are
inspired => inspir
by => by
our => our
convictions. => convictions.
Lemmatization Versus Stemming#

Sentence Segmentation#
Sentence segmentation breaks up text using sentence boundaries.
doc = nlp("I love coding and programming. I also love sleeping!") # string
for sent in doc.sents: # segment sentences
print(sent.text) # show output
I love coding and programming.
I also love sleeping!
Additional Resources#
We’ve already seen some of these workflows in action:
Jupyter Notebook for Elements I (F23) NLP explorations
Jupyter Notebook from our South Bend State of the City NLP explorations
Tutorials that are a good starting point: